论文题目: Multi-feature output deep network ensemble learning for face recognition and verification
人工智能与视觉检测团队李朝荣教授近日在国际知名期刊《Signal Image and Video Processing》上发表了一篇创新性的研究论文。
在现实场景中,人脸数据的采集通常受到诸多限制,导致样本规模有限,这使得通过预训的深度神经网络模型(DCNNs)进行迁移学习以提高识别性能成为一项具有挑战性的任务。此外,在复杂多变的环境下,单一DCNN模型的识别性能也会显著降低。
为了解决这一系列问题,团队在论文中提出了一种基于机器学习的多特征DCNN集成学习方法,以实现人脸识别和验证的效果优化(图一)。首先,通过扩展DCNN模型输出的特征维度,增强了对人脸细节的精准提取能力(图二)。接着,采用参数较少或无参数的机器学习方法对小样本数据库进行二次学习,从而提取更具辨别力的特征。在研究中,团队充分利用了ResNet50、SENet等几种主流网络模型,将特征进行扩展与整合。实验证明,团队提出的方法使得现有DCNN模型的识别和验证精度得到了高达10%的显著提升。
值得一提的是,这一方法无需耗费大量时间进行网络训练,相对于传统方法,计算成本大幅降低,具有广泛的实用价值。这一研究成果不仅在人脸识别技术的前沿研究中取得了突破,同时也为相关领域的发展提供了有力支持。
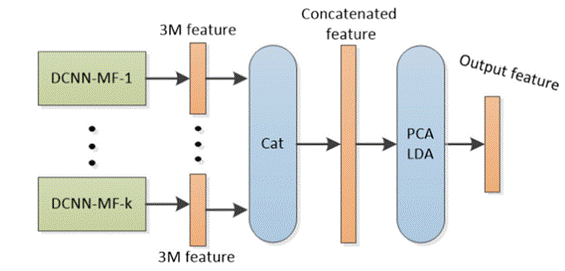
图一、多特征输出深度网络集成
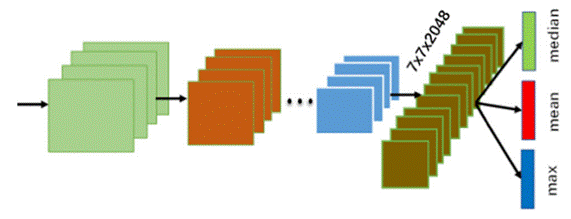
图二、多特征输出深度网络
论文地址:https://link.springer.com/article/10.1007/s11760-023-02798-3
